

I took photos with my phone from three distinct locations, rotating the camera at each spot.
Original images:




A homography matrix \( H \) relates points in one image to corresponding points in another image:
Expanding above,
For each pair of corresponding points \( (x, y) \) and \( (x', y') \), two equations can be set up:
\( H[0,0] \cdot x + H[0,1] \cdot y + H[0,2] - x' \cdot (H[2,0] \cdot x + H[2,1] \cdot y + H[2,2]) = 0 \)
\( H[1,0] \cdot x + H[1,1] \cdot y + H[1,2] - y' \cdot (H[2,0] \cdot x + H[2,1] \cdot y + H[2,2]) = 0 \)
We build a matrix \( A \) from the equations above. For each point pair, we have:
\([x, y, 1, 0, 0, 0, -x' \cdot x, -x' \cdot y, -x']\)
\([0, 0, 0, x, y, 1, -y' \cdot x, -y' \cdot y, -y']\)
This produces a system \( A \cdot h = 0 \), where \( h \) is a vector of the 8 unknowns in \( H \).
To solve for \( H \), I used Singular Value Decomposition (SVD) to estimate Homography Matrix.
The warpImage function takes an image and a homography matrix H as inputs to warp the image according to the transformation described by H. The function defines the four corners of the image and applies the inverse of the homography matrix to transform these corners, calculating the minimum and maximum x and y coordinates to determine the size of the output canvas. If the transformed coordinates extend beyond the image boundaries, it calculates offsets to ensure the entire transformed image fits within the new canvas dimensions.
The function uses these transformed coordinates to generate a polygon that encompasses the new boundaries. It then constructs the homogeneous coordinates of points within this polygon and maps them back to the source image using the homography matrix. To perform this transformation, the function uses inverse mapping and normalizes the coordinates.
Next, it creates a grid of points corresponding to the pixel locations in the source image, and initializes an empty canvas for the warped image with the computed size. The function then applies scipy.interpolate.griddata to interpolate pixel values from the source image for each channel individually. It uses the nearest neighbor method to fill the pixels in the warped image based on the transformed coordinates.
Finally, the function assigns the interpolated pixel values to the appropriate locations in the new canvas.
Here are the wraped results:



To rectify images, the warpImage function is used with inverse warping. Inverse warping involves applying the inverse of the homography matrix, which transforms the coordinates of the distorted image back to their original, undistorted positions.
By using inverse warping, the function interpolates pixel values from the source image to fit a new, rectified view. The result is an image that appears as if it were taken from a frontal perspective.




This process combines two images using Laplacian stack from project 2. The blending process involves the following steps:
warpImage function from previous parts.
Here are final results:



Working with front warping and inverse warping was tricky and required careful consideration of coordinate transformations. It took a significant amount of time to debug, but it was interesting overall as I could experiment with distorting images from different perspectives.
The Harris Corner Detector identifies corners by finding points in an image where the intensity changes significantly in both the x and y directions.
I used the provided harris.py code to apply this process. Below is a figure showing the Harris corners overlaid on the image.






h based on the input coordinates coords.c_robust=0.9, ensuring that only points with significantly lower responses are suppressed.max_features=250. These points represent the most robust features with good spatial distribution.The anms function effectively filters out non-robust features while keeping the well-distributed corners.
The results below show the key points selected through ANMS:






40x40 patch centered on the point is extracted from the image.8x8 patch.The resulting feature descriptors are used to match the set of images.
Below are the extracted and normalized patches of one of the images:

The feature matching process compares descriptors from two images to identify corresponding features.
descriptor1 (from Image 1), the Euclidean distance to every descriptor in descriptor2 (from Image 2) is computed.ratio_threshold) than the distance to the second nearest match, the match is retained.This matching process yields pairs of points from both images that are likely to correspond.
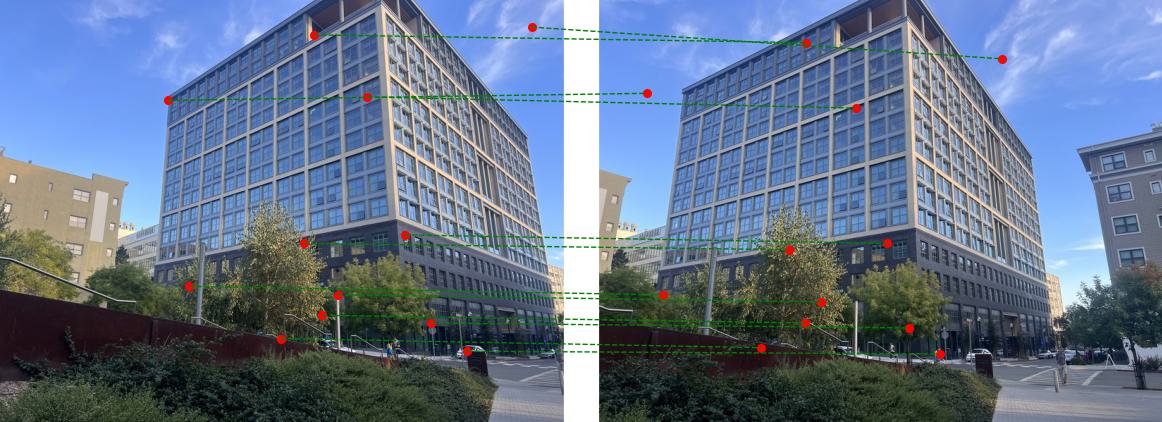
Here are the results of the matched features across the set of images:



H is computed using the selected pairs.H, points from the first image are transformed, and their distances to corresponding points in the second image are calculated. If the distance is below a threshold, the point pair is considered an inlier.H with the largest inlier set is retained as the best fit.H is computed using all inliers to increase accuracy.By iteratively refining the homography based on inliers, RANSAC provides a robust estimate of the transformation.
Below are the results of the RANSAC process across the set of images:


Below are the results of three mosaics: automatically stitched and manually stitched, respectively.



There is not a significant visual difference between the manually stitched and automatically stitched versions. Both methods align the images well. The automatic stitching algorithm effectively aligns key features without noticeable misalignments.